此项目使用MPI单程序多数据(SPMD)分布式内存并行性来运行模具代码,从assignment 1 的在一个核心上运行拓展到在两个节点的所有核心(共56个核心)上运行。项目代码:Distributed Memory Parallelism With MPI
1. 介绍
此项目的目的是使用MPI对assignment1优化后的stencil代码基础上并行优化。该文章首先将讨论一些重要的MPI通信。接下来,此报告将介绍如何分别沿列和行分解原始图像,以及如何为每个rank分配特定的值。然后,本文将描述光环交换(halo exchange),该交换可帮助每个进程从相邻进程获取所需数据。本报告还会涉及到从所有过程定时收集数据的过程。 最后,将分享性能改进的说明和内核数量数据分析。
2. MPI通信
MPI是标准的消息传递接口,在并行计算机上得到了广泛的使用。MPI通信主要包括点对点和集体通信。
为了确保正确发送和接收消息,在此项目中笔者使用了阻塞点对点通信。 MPI_Send调用可以将信息从一个进程转移到另一进程。 MPI_Recv方法可以接收到其他进程的消息,并且一直维持阻塞状态直到收到消息为止。MPI_Sendrecv调用可以同时发送消息和接收消息。
除了点对点通信外,最重要的集体通信——MPI_reduce也在此项目中有运用。 MPI_Reduce的功能是在同一通信器的每个进程中共享对数据执行二进制操作。
3. 区域分解
首先,将输入图像的大小设置为nx(行数)* ny(列数)。对于5点模板功能,此图像应被一圈零包围,从而得到新的图像尺寸。 新图像的宽度为ny + 2,高度为nx + 2。在代码分配大小为ny + 2 * nx + 2的数组之后,通过调用init_image()函数将图像初始化为棋盘图案。
在那之后,为了使用MPI通信,图像网格将根据进程数N划分为N个子网格。由于项目的要求,代码中应使用两个节点,每个节点有28个核心。因此,总进程数为56。
网格将被平均分为56个部分。但是,当行数或列数除以进程数时,有时会产生余数。为了合理解决这个问题,多余的行数或列数将被添加到最后一个进程。
3.1 按列分解
根据下图,输入图像将被按列划分为N个子网格。 除最后一个进程外,其他每个进程都会具有相同的大小。calc_ncols_from_rank()函数将计算每个进程的列数。每个进程将获得X维度的一部分和Y维度的整个范围。最后一块分配的列最多,因为它将被添加额外的余数列数。
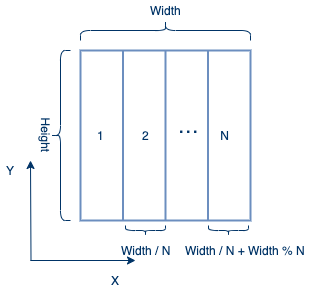
该代码将为每个进程分配一个新的数组。其中当前图像的第一列和最后一列均为零列。分解图像后,第一个进程的第一列和最后一个进程的最后一列将为零列。在接下来的步骤中,所有进程都必须进行光环交换。因此,应将每个进程添加一个晕圈区域。因为分配时,已经为第一个进程和最后一个进程分配了一列零列,因此只需要为这两个进程添加额外的一列,而其他进程需要被添加额外的两列。
创建局部网格(即当前进程的网格部分)后,将网格的核心单元设置为初始化图像的相应值,而将晕圈单元设置为零值。
3.2 按行分解
笔者首先尝试了按列分解输入图像。由于主要数据布局是按行的,所以按列分配时给每个进程分配相应的值非常不方便。因此,产生了将输入图像沿行分解为N个部分的想法。
如下图所示,每个进程具有相同的宽度和新的高度,最后一个进程可能会被分配到最多的行数。
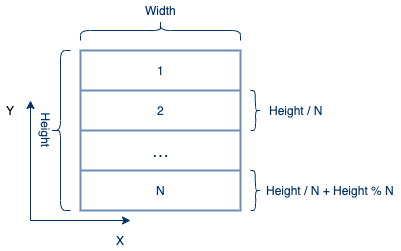
根据下表,按行分解的运行时间略微比按列分解的运行时间短,因为前者可以使用连续分配。在本报告的以下各节中,将仅提及按行分解,不再提及按列分解。
| 尺寸 | 1024*1024 运行时间 | 4096*4096 运行时间 |
|---|---|---|
| 1024*1024 | 0.039379 秒 | 0.028604 秒 |
| 4096*4096 | 0.229268 秒 | 0.180593 秒 |
| 8000*8000 | 1.320589 秒 | 1.241563 秒 |
4. 光环交换
原始图像被分为N个部分,N个过程同时执行相同的操作。5点模具代码将网格中每个单元的值都更新为相邻的北,南,东和西单元的平均值。这就导致每个进程里有大量的核心单元需要获得来自其他进程的相邻单元的数据。
为了读取位于不同进程上的邻居值,光晕区域将被添加到每个处理器边界,并用来自相邻进程的数据副本填充光晕区域。根据下图可见,第一个进程只需在本地网格下添加一行光晕区域,最后一个进程只需要在本地网格上添加一行光晕区域,但其他进程必须在本地网格上方和下方分别添加一个晕圈区域。这是由于第一个和最后一个进程已经分配了一行零行。
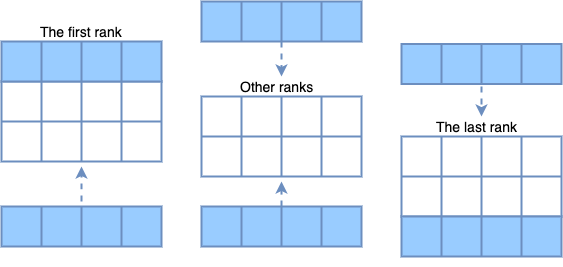
在为所有处理器添加对应的光晕区域后,将通过调用MPI_Sendrecv函数来发送和接收来自相邻进程的数据。如下4所示,代码将数据打包到一个数组中,然后将数组发送到那些相邻的进程,同时还需要对从其他进程来接收到的缓冲区进行解包。每个进程都需要将消息发送到上一个和下一个进程,并从它们接收消息。因此,光环交换应首先将消息发送到上层网格并从下层网格中接收,然后将消息发送到下层网格并从上层网格中接收。
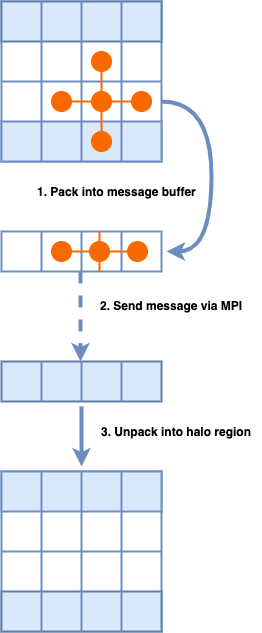
每次迭代都应更新包括核心单元和晕圈单元在内的所有单元。每个进程的核心单元将通过调用stencil函数进行更新,而光环单元则需要通过进行光环交换来更新,这使得每个迭代变为两个步骤。第一步是交换光晕区域,第二步是调用stencil函数用来计算核心单元的新值。
5. 数据收集和计时器
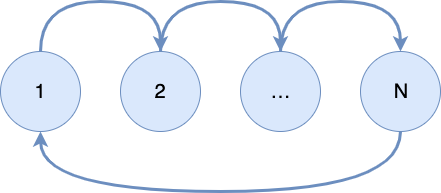
当所有过程完成计算后,系统应从每个过程中收集处理后的网格。从下图中可以看出,第一进程将首先用本地网格的计算值替换image数组的相应值。接下来,第二个进程接收修改后的image数组并替换其对应行的值。每个进程都会做同样的事情直到最后一个进程。最后一个进程将修改image数组,然后将修改好的image数组发送到第一个进程。第一个进程接收此数组后,调用output_image函数输出新图像。
系统计时器仅计时代码的光环交换和主计算循环。为了打印正确的运行时间,MPI_Reduce函数用于获取所有进程中的最早开始的进程开始时间和最晚结束的进程结束时间,打印的运行时间即是这两者时间之差。
说明和数据分析
下表证明了分布式内存并行性显著提高了代码性能。assignment1的串行模板代码必须计算整个图像,而本文的方法将输入图像划分为56个小图像,这些图像可以通过MPI同时计算,从而节省了大量运行时间。
| 尺寸 | 优化前 | 优化后 |
|---|---|---|
| 1024*1024 | 0.110686 秒 | 0.028604 秒 |
| 4096*4096 | 2.878536 秒 | 0.180593 秒 |
| 8000*8000 | 10.348350 秒 | 1.241563 秒 |
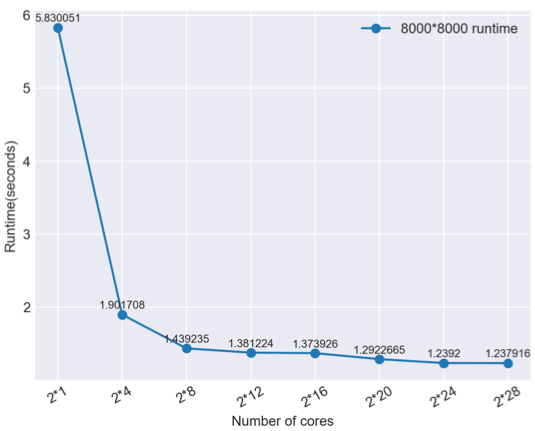
根据下图,以8000 * 8000输入图像为例,很明显,节点数数与运行时间之间存在非线性关系。 随着内核数量的增加,对运行时间的影响变得不那么明显。
引用
[1] Walker D W, Dongarra J J. MPI: a standard message passing interface[J]. Supercomputer, 1996, 12: 56-68.
[2] Makpaisit P, Ichikawa K, Uthayopas P, et al. MPI_Reduce algorithm for OpenFlow-enabled network[C]//2015 15th International Symposium on Communications and Information Technologies (ISCIT). IEEE, 2015: 261-264.