该项目旨在对五点模具代码进行优化,以期提高在超算bluecrystal4上的性能。项目代码:Serial Optimisation
介绍
该任务旨在优化串行5点模具代码以提高性能。该报告将首先介绍不同版本的GCC的影响。 然后,笔者将测试一些编译器标志为了选择最佳标志。 接下来,编译器将使用restrict关键字对代码进行矢量化处理。该报告还描述了分别修改数据布局和数据类型的不同结果。最后,本文将介绍一些尝试过但无法成功提高代码性能的其他优化。
GCC版本
Bluecrystal4上的默认GCC版本为V4.8.5。通常而言,最新的编译器版本在某种程度上会比旧版本提高一定性能。根据下表,很明显可知,当GCC版本更新到9.1.0之后,减少了程序一定的运行时间。
| 实例数量 | 1024*1024 运行时间 | 4096*4096 运行时间 | 8000X8000 运行时间 |
|---|---|---|---|
| 4.8.5 | 4.617649 秒 | 110.034755 秒 | 507.495510 秒 |
| 9.1.0 | 4.584941 秒 | 105.331533 秒 | 481.602353 秒 |
优化选项
最新的GCC版本可以在某种程度上减少运行时间,但是此时没有使用任何的优化选项,编译器只是旨在降低复杂度成本,而不是减少复杂度时间。为了加快运行时间,必须打开优化选项。GCC编译器提供了一些可以启用不同优化程度的选项。 当用户为代码设置优化选项时,编译器将尝试减少编译时间和调试能力以提高性能。
下表显示了每个优化选项设置后的三个运行时间。 如果用户未为代码设置任何优化级别,而代码无法进行任何优化,-O0 标志是默认选项。 -Ofast -mtune = native选项可打开五个选项中的最大优化程度。 因此,在指定优化级别后,运行时间明显有减少。
| 尺寸 | -O0 | -O1 | -O2 | -Ofast | -Ofast -mtune=native |
|---|---|---|---|---|---|
| 1024*1024 | 4.508 秒 | 1.495 秒 | 1.504 秒 | 0.905 秒 | 0.897 秒 |
| 4096*4096 | 103.248 秒 | 42.765 秒 | 34.617 秒 | 34.468 秒 | 33.908 秒 |
| 8000*8000 | 480.012 秒 | 151.898 秒 | 153.434 秒 | 138.468 秒 | 135.999 秒 |
restrict 关键字
很明显,GCC编译器通过优化选项提高了性能。 但是,代码仍然需要更多的优化。
矢量化是实现高性能的关键工具。 通过矢量化,编译器生成打包的SIMD指令,这些指令一次可操作多个元素。 因此,循环可以更有效地执行。在上一部分中,我们的Makefile文件中指定了优化选项 -Ofast -mtune = native,并且该选项打开了自动矢量化标志。 由于该标志,编译器将寻求向量化机会。循环将在向量化期间查找别名。如果在指针声明中使用了restric关键字,则编译器将不对别名进行任何检查。因此,运行时间将缩短。下表展示了运行时间有一定减少。
| 尺寸 | 未使用restrict关键字 | 使用restrict关键字 |
|---|---|---|
| 1024*1024 | 0.900453 秒 | 0.741756 秒 |
| 4096*4096 | 33.891886 秒 | 33.524914 秒 |
| 8000*8000 | 140.521839 秒 | 122.268852 秒 |
数据布局
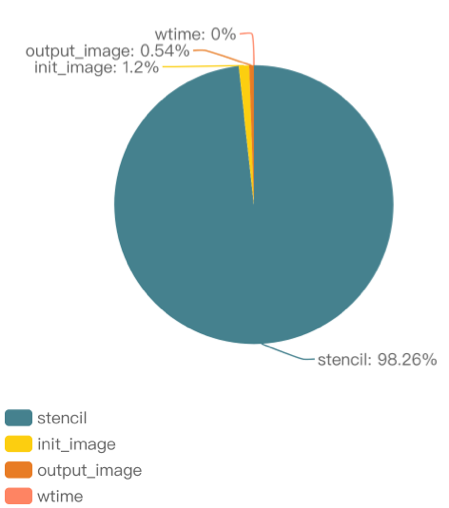
gprof分析器可以找出昂贵的函数在哪里。 探查器为5点模板代码生成一个探查报告。 根据饼图可见,stencil函数是四个功能的重要组成部分,大约占总运行时间的98%。 经过检查源代码,发现stencil函数未连续读取数组数据。 为了程序能够连续读取数据,需要交换里外循环的两个迭代变量顺序。 表格数据证明了循环交换可以明显提高运行性能。
| 尺寸 | 未使用restrict关键字 | 使用restrict关键字 |
|---|---|---|
| 1024*1024 | 0.719312 秒 | 0.181445 秒 |
| 4096*4096 | 31.960942 秒 | 5.849982 秒 |
| 8000*8000 | 124.914562 秒 | 22.270323 秒 |
数据类型
除了数据布局之外,数据类型也能影响代码性能。 显然,较小的类型使用较少的内存并提供更快的计算。 在此实验中,实验者将双指针转换为浮点指针。 根据下表,可见较小的数据类型的确可以节省运行时间。
| 尺寸 | Double类型 | 使用restrict关键字 |
|---|---|---|
| 1024*1024 | 0.181445 秒 | 0.110686 秒 |
| 4096*4096 | 5.849982 秒 | 2.878536 秒 |
| 8000*8000 | 22.270323 秒 | 10.348350 秒 |
其他优化
上面没有提到的一些优化也是有一定效果的。 例如,英特尔编译器是一个非常很好的编译器,它在默认情况下会自动打开一些标志。 预取(prefetching)也是将数据带入缓存的可行方法。 尽管平铺(tiling)是值得考虑的一种优化方法,但是5点模具代码的主要功能里没有三个或更多的循环,这导致无法使用平铺。
结论
在此报告中,进行了大量实验测试,以获得目标运行时间。 最后,代码中应用了五种优化方式。这些优化方式使得代码分别可以在0.11秒,2.88秒和10.35秒内执行完毕。
引用
[1] Gcc.gnu.org. (2019). Optimize Options - Using the GNU Compiler Collection (GCC). [online] Available at: https://gcc.gnu.org/onlinedocs/gcc-4.4.2/gcc/Optimize-Options.html [Accessed 24 Oct. 2019].
[2] Software.intel.com. (2019). A Guide to Vectorization with Intel® C++ Compilers. [online] Available at: https://software.intel.com/sites/default/files/m/4/8/8/2/a/31848-CompilerAutovectorizationGuide.pdf [Accessed 25 Oct. 2019].